
Data privacy and data classification play an increasingly important role in every aspect of life, from businesses to individuals. Let’s explore these important concepts in detail and why they play a decisive role in today’s digital world.
Definition of data privacy and data classification
Data Privacy
Definition: Data privacy refers to the protection of personal information or sensitive data from unauthorized access, disclosure, alteration, or destruction. It involves the proper handling, storage, and sharing of individuals’ data to ensure confidentiality and maintain trust.
Key Aspects:
- Control over personal information.
- Consent and transparency in data collection.
- Safeguards against unauthorized access or breaches.
- Compliance with privacy regulations and laws.

Examples
- Safeguarding user credentials.
- Encrypting sensitive data during transmission.
- Implementing privacy policies and notices.
Data Classification
Definition: Data classification is the process of categorizing and organizing data based on its sensitivity, importance, or value. It involves labeling and assigning levels of security to different types of data, making it easier to manage, control access, and apply appropriate security measures.
Key Aspects
- Identifying and labeling data based on attributes.
- Assigning levels of sensitivity or confidentiality.
- Implementing access controls according to data classification.
- Facilitating efficient data management and protection.
Examples
- Classifying data as public, internal, confidential, or restricted.
- Applying encryption to highly sensitive information.
- Defining user access permissions based on data classification.
The importance of data privacy and data classification
The importance of data privacy and data classification cannot be overstated in today’s digital age, where vast amounts of information are generated, collected, and processed. Both concepts play critical roles in safeguarding sensitive information, ensuring regulatory compliance, and maintaining trust in various domains. Here are key reasons highlighting their significance:
Data Privacy
Protection of Personal Information
Safeguarding individuals’ personal data from unauthorized access, ensuring their privacy and preventing identity theft.

Trust and Reputation
Building and maintaining trust with customers, clients, and stakeholders by demonstrating a commitment to protecting their sensitive information.
Legal Compliance
Adherence to data protection laws and regulations, such as GDPR (General Data Protection Regulation), CCPA (California Consumer Privacy Act), and others, to avoid legal consequences and financial penalties.
Minimizing Security Risks
Mitigating the risk of data breaches, cyberattacks, and unauthorized disclosure, which can have severe consequences for both individuals and organizations.
User Control and Consent
Providing individuals with control over how their data is collected, used, and shared, and obtaining explicit consent for processing sensitive information.
Business Continuity
Protecting critical business data to ensure continuity and resilience against potential disruptions caused by data breaches.
Data Classification
Risk Management
Identifying and prioritizing data based on its sensitivity allows organizations to allocate resources and implement security measures according to the level of risk associated with each type of data.
Efficient Data Handling
Streamlining data management processes by categorizing information helps organizations organize, store, and retrieve data more efficiently.
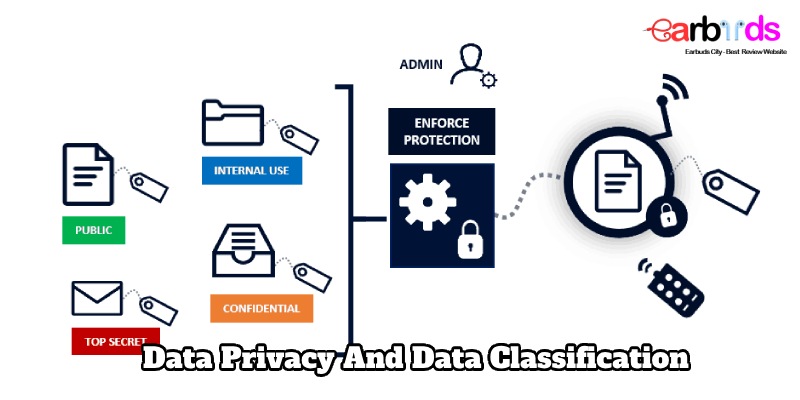
Access Control
Implementing granular access controls based on data classification ensures that only authorized individuals have access to sensitive information, reducing the risk of insider threats.
Regulatory Compliance
Meeting regulatory requirements by categorizing and protecting data in accordance with industry-specific and regional regulations.
Intellectual Property Protection
Safeguarding intellectual property and proprietary information through proper classification and control mechanisms.
Incident Response
Facilitating a faster and more targeted response to security incidents by quickly identifying and addressing breaches or unauthorized access to sensitive data.
Resource Optimization
Allocating security resources more effectively by focusing on protecting the most critical and sensitive data within an organization.
What are data classification methods?
Data classification methods involve categorizing and organizing data based on its sensitivity, importance, or value. The goal is to assign appropriate security measures to protect data according to its classification level. Here are some common data classification methods:
Content-Based Classification
Description: Classifying data based on its content, including keywords, patterns, or file types. This method is often used for identifying sensitive information within documents, emails, or other textual data.
Example: Using content inspection tools to detect credit card numbers, Social Security numbers, or other sensitive information in emails or documents.
Context-Based Classification
Description: Considering the context in which data is used or stored to determine its classification. This method takes into account factors such as user roles, project types, or business processes.
Example: Classifying data differently based on whether it is used in a research and development context or in a public-facing application.
User-Based Classification
Description: Allowing users to classify data based on their understanding of its sensitivity. This method often involves providing users with tools or interfaces to tag or label data.
Example: Users marking an email or document as “confidential” or “public” to indicate the level of sensitivity.
Time-Based Classification
Description: Assigning different classification levels to data based on its relevance or sensitivity over time. Data may be classified as highly sensitive during its creation and then downgraded as it becomes less critical.
Example: Research data that is classified as highly sensitive during active research but may be downgraded after a certain period.

Automatic Classification
Description: Implementing automated tools or algorithms to analyze data and assign classification labels based on predefined rules or machine learning models.
Example: Using machine learning algorithms to analyze patterns and automatically classify emails or documents as sensitive or non-sensitive.
Regulatory-Based Classification
Description: Aligning data classification with specific regulatory requirements and compliance standards. This method ensures that data handling practices adhere to legal obligations.
Example: Classifying healthcare data in accordance with Health Insurance Portability and Accountability Act (HIPAA) regulations.
Pattern Matching and Data Profiling
Description: Identifying data patterns and profiles to classify information based on common characteristics or attributes.
Example: Analyzing data to recognize patterns such as credit card numbers or personally identifiable information (PII) and classifying data accordingly.
Location-Based Classification
Description: Assigning classification levels based on the physical or logical location of data. Different security measures may be applied depending on whether data is stored on-premises, in the cloud, or in specific geographic locations.
Example: Classifying data stored on a secure server differently from data stored on an employee’s local machine.
In conclusion
Data privacy and data classification is not only a business task but also a global community responsibility. We not only build trust in the use of data but also create a digital environment that is safe, transparent and sustainable.


